


Dans le monde actuel axé sur les données, les organisations traitent d'énormes quantités de données qui nécessitent une gestion et une analyse appropriées. Un aspect crucial de cette gestion des données est le processus ETL (Extract, Transform, Load).
L'ETL est une approche systématique qui consiste à extraire des données de diverses sources, à les transformer dans un format cohérent et à les charger dans une destination cible. Ce guide complet vous fera découvrir le processus ETL, ses étapes, ses meilleures pratiques, ses outils et ses défis.
Qu'est-ce que le processus ETL ?
ETL est l'acronyme de Extract, Transform, Load (extraction transformation et chargement). Il s'agit d'un processus utilisé pour collecter des données à partir de différentes sources, les modifier et les nettoyer, puis les charger dans un système ou une base de données cible. Chaque composant de l'ETL joue un rôle essentiel dans l'intégration précise et fiable des données.
Les étapes du processus ETL
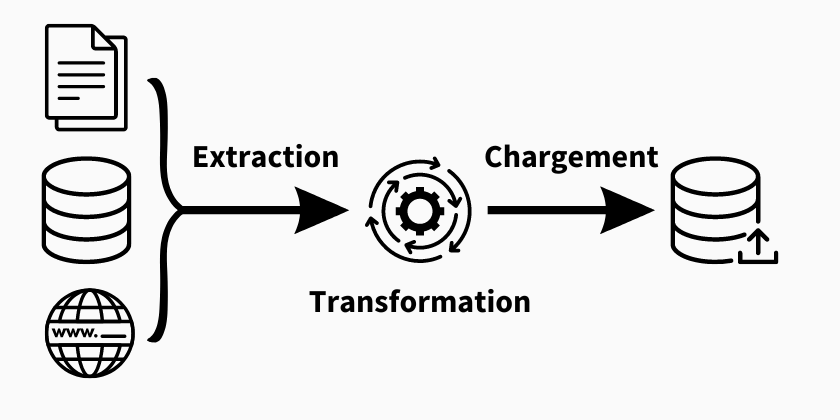
EXTRACTION DES DONNÉES
Pour lancer le processus ETL, la première étape consiste à extraire les données à partir dee sources pertinentes. Il peut s'agir de diverses origines de données, telles que des bases de données internes, des logiciels CRM, des lacs de données, des plateformes d'automatisation du marketing, des entrepôts de données dans le cloud, des fichiers structurés et non structurés, des applications dans le cloud ou toute autre source de données préférentiel. Les données extraites peuvent être des données structurées et non structurées.
Quelles sont les techniques d'extraction disponibles ?
- Extraction manuelle - L'extraction manuelle des données consiste à saisir ou à copier manuellement des données provenant de différentes sources. Cette méthode convient à l'extraction de données à petite échelle, mais elle peut prendre beaucoup de temps et être source d'erreurs.
- Extraction automatisée - L'extraction automatisée utilise des outils logiciels ou des scripts pour extraire automatiquement des données brutes de différentes sources. Elle permet de gagner du temps et de réduire les erreurs, ce qui la rend idéale pour l'extraction de données à grande échelle.
Quelles sont les différentes sources à partir desquelles des données peuvent être extraites ?
- Bases de données relationnelles - Vous pouvez extraire des données à partir de systèmes de gestion de bases de données tels que MySQL, Oracle, SQL Server, PostgreSQL, etc.
- Flat files - Vous pouvez extraire des données de fichiers à deux dimensions tels que les fichiers CSV, les fichiers Excel, les fichiers texte délimités, etc.
- API - De nombreuses applications et de nombreux services exposent des API qui permettent de programmer l'extraction de données. Par exemple, les API RESTful ou SOAP peuvent être utilisées pour extraire des données de services web.
- Sources web - Vous pouvez extraire des données de sites web à l'aide de techniques de web scraping, qui consistent à extraire des informations du code HTML des pages web.
- Entrepôts de données dans le cloud - Les plateformes telles que Salesforce, Amazon Web Services (AWS), Google Cloud Platform (GCP) et Microsoft Azure offrent des services spécifiques pour l'extraction de données à partir de leurs environnements.
- Flux de données en temps réel - Pour les données en temps réel, vous pouvez extraire des données à partir de systèmes de flux tels que Apache Kafka, Apache Flink, ou en utilisant des outils de capture de flux de données.
Nos données B2B jouent un rôle important dans le processus ETL auquel sont soumises presque toutes les entreprises. Chez InfobelPro, nous structurons spécifiquement les données provenant de plus de 1100 sources diverses. Nous créons des formats uniques pour toutes les données commerciales mondiales grâce à nos équipes d'experts qui nettoie et transforme les données. Nous pouvons fournir à la fois des données structurées et non structurées.
Vous souhaitez plus d'informations ? Visitez notre page de contact pour prendre contact avec nous.
TRANSFORMATION DES DONNÉES
Une fois les données extraites, elles doivent être transformées dans un format cohérent qui convient au data warehouse (entrepôt de données), au système ou à la base de données cible. Cette étape implique le nettoyage des données, la validation, la normalisation, l'agrégation et l'enrichissement des données.
Pour répondre aux exigences du schéma de la base de données cible, les données extraites sont manipulées à l'aide d'une série de fonctions et de règles. L'ampleur de la transformation requise dépend largement de la nature des données extraites et des besoins spécifiques de l'entreprise.
Quelles sont les différentes étapes de la transformation des données ?
- Nettoyage des données - Suppression des valeurs manquantes, des doublons, des données incorrectes ou incohérentes.
- Normalisation et standardisation - Harmonisation des formats de données tels que les formats de date, les codes postaux, les numéros de téléphone, etc.
- Agrégation - Regroupement des données pour obtenir des statistiques agrégées, telles que la somme, la moyenne, le maximum, le minimum, etc.
- Jonction et fusion - Combinaison de données provenant de différentes sources à l'aide de clés communes pour créer une vue consolidée.
- Filtrage et sélection - sélectionner uniquement les données pertinentes à charger, à l'aide de critères spécifiques.
- Calculs dérivés - effectuer des calculs sur des données existantes pour générer de nouvelles valeurs ou des indicateurs supplémentaires.
CHARGEMENT DES DONNÉES
L'étape finale est le chargement des données, où les données transformées sont chargées dans le système ou la base de données cible. Les données chargées peuvent être stockées dans un entrepôt de données, un datamart ou une base de données spécifique en vue d'une analyse et d'un rapport ultérieurs.
Quelles sont les différentes méthodes de chargement des données ?
- Chargement en masse - Chargement de données par lots, en utilisant des requêtes SQL massives pour insérer ou mettre à jour des enregistrements dans la base de données cible. Le chargement en masse convient lorsque vous avez un grand volume de données à charger dans la base de données cible.
- Chargement incrémentiel - Chargement des seules données qui ont été modifiées depuis la dernière exécution du processus ETL, à l'aide de mécanismes tels que les horodatages ou les marqueurs de date/heure. Le chargement incrémentiel est utile lorsque vous souhaitez charger uniquement les données qui ont été modifiées depuis la dernière exécution du processus.
- Insertion en temps réel - Chargement des données au fur et à mesure de leur arrivée, à l'aide de mécanismes de diffusion en continu ou d'outils de traitement des flux. L'insertion en temps réel est utilisée lorsque la disponibilité immédiate des données est cruciale et qu'il faut charger les données dès leur arrivée dans le système.
- Chargement parallèle - Le chargement parallèle répartit les données entre plusieurs processus de chargement ou serveurs simultanément. Le chargement parallèle est utile lorsque vous disposez d'un grand ensemble de données et que vous souhaitez optimiser la vitesse et les performances de chargement.
- Chargement par lots planifié - Planification des tâches de chargement à intervalles réguliers, à l'aide d'outils d'automatisation des tâches ou de planificateurs de tâches. Cette technique est utile lorsque les données sont mises à jour à intervalles prévisibles et que vous souhaitez automatiser le processus de chargement.
Les avantages du processus ETL
Le processus ETL offre de nombreux avantages aux organisations qui s'occupent de l'intégration et de la gestion des données. Examinons quelques-uns des principaux avantages de la mise en œuvre d'un processus ETL :
- Précision accrue des données - Améliore la précision des données grâce à des techniques de nettoyage, de validation et d'enrichissement, garantissant ainsi des données de haute qualité pour l'analyse et la prise de décision.
- Amélioration de la cohérence des données - Normalisation et transformation des données provenant de diverses sources dans un format cohérent, ce qui facilite une intégration transparente et des comparaisons précises.
- Réduction de la duplication des données - En employant des techniques de déduplication des données, le processus ETL identifie et élimine les enregistrements en double, garantissant une source unique de vérité et évitant les coûts de stockage inutiles.
- Accès plus rapide aux données - Les données sont organisées dans un format unifié, ce qui permet un accès rapide et efficace aux rapports, à l'analyse des données et à la prise de décision en temps voulu.
- Amélioration de la sécurité des données - Mise en œuvre de mesures de sécurité telles que les contrôles d'accès, le cryptage et le masquage, garantissant la sécurité des données, le respect de la vie privée et le maintien de l'intégrité des données.
Les bonnes pratiques du processus ETL
Le processus d'extraction, de transformation et de chargement des données, joue un rôle essentiel dans la réussite de l'intégration et de l'analyse des données.
Pour garantir un traitement efficace et fiable des données, les entreprises adoptent diverses bonnes pratiques qui contribuent à optimiser le processus ETL :
- Analyse et profilage des données - Avant de commencer le processus ETL, il est essentiel d'analyser et de profiler les données sources pour comprendre leur structure, leur qualité et leurs relations.
- Traitement des erreurs et contrôle de la qualité des données - La mise en œuvre de mécanismes robustes de traitement des erreurs et la réalisation de contrôles de la qualité des données à chaque étape du processus ETL garantissent une intégration fiable des données.
- Sécurité des données et conformité - Garantir la sécurité des données et la conformité avec les réglementations en matière de protection de la vie privée en mettant en œuvre des mesures de sécurité, des contrôles d'accès et des techniques de cryptage appropriés.
- Documentation et contrôle des versions - Maintenir une documentation détaillée du processus ETL, y compris les mappages de données, les transformations et les règles de gestion. Utilisez le contrôle des versions pour suivre les modifications et garantir la reproductibilité.
Outils et technologies ETL
Il existe sur le marché plusieurs outils ETL qui facilitent le processus ETL. Parmi les outils les plus populaires, citons Informatica PowerCenter, Talend, Microsoft SQL Server Integration Services (SSIS) et Apache Nifi. Ces outils offrent des fonctions d'extraction, de transformation et de chargement des données, ainsi que des capacités de planification, de surveillance et de traitement des erreurs. Il est essentiel de choisir un outil qui réponde aux besoins spécifiques de votre organisation.
Les défis du processus ETL
Si le processus ETL offre de nombreux avantages en termes d'intégration et d'analyse des données, il n'est pas sans poser de problèmes. Les entreprises sont confrontées à divers obstacles qui peuvent avoir un impact sur l'efficacité, l'évolutivité et la sécurité du processus ETL.
Ces défis englobent les complexités liées à l'intégration des données, les problèmes d'évolutivité et de performance, ainsi que les questions de gouvernance des données et de confidentialité :
- Complexité de l'intégration des données - L'intégration de données provenant de sources multiples dont les formats, les structures et les niveaux de qualité varient peut s'avérer difficile. Elle nécessite un mappage et une transformation minutieux des données.
- Problèmes d'évolutivité et de performance - La manipulation de gros volumes de données et la garantie d'une performance efficace pendant le processus ETL peuvent s'avérer difficiles. Les techniques d'optimisation telles que le traitement parallèle et le partitionnement des données peuvent résoudre les problèmes d'évolutivité.
- Gouvernance des données et problèmes de confidentialité - Le maintien de la gouvernance des données, la garantie de la confidentialité des données et la conformité à des réglementations telles que le GDPR et le CCPA sont des aspects cruciaux du processus ETL. La mise en œuvre de mesures de sécurité et de contrôles d'accès appropriés est nécessaire.
Futures Tendances du processus ETL
Le domaine du processus ETL évolue continuellement pour répondre aux demandes croissantes d'intégration et d'analyse des données.
Au fur et à mesure que la technologie progresse, plusieurs tendances se dessinent et façonnent l'avenir des processus ETL :
- ETL dans le cloud - Les solutions ETL dans le cloud sont de plus en plus populaires, car elles offrent un certain nombre d'avantages par rapport aux solutions traditionnelles internes, tels que l'évolutivité, la flexibilité et la rentabilité.
- ETL en temps réel - L'ETL en temps réel devient de plus en plus important, car les entreprises doivent pouvoir accéder aux données et les analyser en temps réel pour prendre des décisions pertinentes.
- ETL en libre-service - Les solutions ETL en libre-service sont de plus en plus populaires, car elles permettent aux utilisateurs professionnels d'extraire, de transformer et de charger des données sans avoir besoin de l'aide du service informatique.
- Virtualisation des données - La virtualisation des données est une technologie qui permet aux entreprises d'accéder à des données provenant de sources multiples sans avoir à les déplacer physiquement. Cela peut simplifier le processus ETL et le rendre plus efficace.
- Machine Learning - Le marchine learning est utilisé pour automatiser de nombreuses tâches liées à l'ETL, telles que le nettoyage et le profilage des données. Cela peut contribuer à améliorer la précision et l'efficacité du processus ETL.
Processus ETL : FAQ
QUELLE EST LA DIFFÉRENCE ENTRE L'ETL ET L'ELT ?
L'ETL (Extract, Transform, Load) consiste à extraire des données, à les transformer et à les charger dans un système cible. ELT (Extract, Load, Transform) suit un processus similaire mais charge d'abord les données dans un système cible et effectue ensuite des transformations au sein de ce système.
LE PROCESSUS ETL S'APPLIQUE-T-IL UNIQUEMENT AUX GRANDES ORGANISATIONS ?
Non, le processus ETL s'applique aux organisations de toutes tailles. Toute entreprise qui s'occupe de l'intégration de données provenant de sources multiples peut bénéficier de la mise en œuvre du processus ETL.
COMMENT LA QUALITÉ DES DONNÉES PEUT-ELLE ÊTRE ASSURÉE AU COURS DU PROCESSUS ETL ?
La qualité des données peut être assurée au cours du processus ETL en mettant en œuvre des règles de validation des données, en effectuant le profilage et l'analyse des données et en procédant à des contrôles de qualité des données à chaque étape de l'extraction, de la transformation et du chargement.
QUELS SONT LES DÉFIS COURANTS RENCONTRÉS LORS DE LA TRANSFORMATION DES DONNÉES ?
Les défis les plus courants lors de la transformation des données sont la gestion de mappages de données complexes, le traitement des incohérences de données, la gestion des problèmes de qualité des données et la garantie d'une performance efficace lors du traitement d'importants volumes de données.
EXISTE-T-IL DES OUTILS ETL À CODE SOURCE OUVERT ?
Oui, il existe plusieurs outils ETL open-source, tels qu'Apache Nifi, Talend Open Studio et Pentaho Data Integration. Ces outils offrent des fonctionnalités robustes pour l'extraction, la transformation et le chargement des données, et peuvent être personnalisés pour répondre à des besoins spécifiques.







Commentaires